NoSQL:
- different from sql as it doesn't use a relational data model so is flexible
- doesn't require database schema
efficiency
- All data in oe table so JOINs are faster
- Horizontally scalable, meaning you can just use another shard instead of buying additional hardware
Types of noSQL
- Key value store:
- Specifically built for high-performance requirements and most common.
- Uses key values with pointters to store data.
- All data stored in one table
- Similar to key-value store but has encoding such as xml
- Stores information in columns instead of rows
- They are grouped into families
- Limitless column nesting data model
- Very fast for searches
- Used for graphs (duh)
- Uses relationships and nodes, data is the information
- relationship is formed between the nodes
RDMBS
- Is a relational database management system to interact with a relational database
- Unlike a DBMS, Uses normalizatio, primary and foreign keys, integrity checks and ACID properties to ensure data
is reliable.
The 3 V's of data science
- Volume
- This is how much data is stored and is obviously key when talking about 'big' data
- Velocity
- Velocity is the growth of the data, and the importance of it.
- It measures how fast the data is coming in.
- Variety
- Things such as video, text and pdf are examples of non-traditional forms of data that need to be dealt
with in big data
Polyglot persistance
- Refers to the value in using multiple data storage technologies for different storage needs.
- No one solution fits all
- Different tech for different kinds of data
Lambda Architecture
- Used to handle massive quantities of data by using both batch and stream-processing methods
3
layers:
- Batch Layer
- Precomputes results with distributed processing system that can handle very large quantities of data.
- Perfect accuracy is required.
- Fixes any errors by recomputing based on the complete data set then updates the existing view, allowing
it to reach perfect accuracy with reversible functions.
- Output is stored in read-only database with updates changing precomputed views.
- This is what Hadoop is and is the leading batch processor.
- Speed layer
- This layer processes data streams in real time without completeness
- Sacrifices throughput as it aims to minimize latency by using real-time views into the data.
- The speed layer is used to fill the "gap" caused by the batch layers lag in providing views
based on the most recent data.
- Not as accureate or complete as the ones eventually produced by the batch layer, but available far
quicker.
- Serving layer
- Output from 2 other layers are stored in the serving layer
- Responds to queries by returning pre-computed views from processed data.
- Cassandra is a dedicated store used in the serving layer.
Hadoop
- written in Java
- Uses large cluster of hardware to maintain big data.
- Works on MapReduce algorithm made by Google.
- Hadoop MapReduce is a programming model for processing big data sets with a parralel distrobuted algorithm.
- One challenge to MapReduce is the sequential multi-step process it take sto run a job. This makes MapReduce jobs
slower because each step requires a disk read and write.
Hadoop MapReduce Phases

- Mapping Phase
- Two steps in this phase, splitting and mapping.
- Data is split into equal units called chunks (input splits) in the splitting step.
- Hadoop consists of a RecordReader that uses TextInputFormat to transform input splits into key-value
pairs
- Key-value pairs are used as inputs in the mapping step.
- Only data format that a mapper can read or understand.
- Mapper processes the key-value pairs and produces an output of the same form (key-value pairs).
- Shuffling phase:
- This phase removes the duplicate values and groups value.
- Different values with similar keys are grouped. the output of this phase will be keys and values, just
like in the mapping phase.
- Reducer phase:
- Outputs of the shuffling phase is used as the input.
- Processes this input more to reduce the intermediate values into smaller values.
- Gives a summary of the entire datasets
Hadoop Distrobuted File System(HDFS)
- Fault-tolerant file system.
- designed to be deployed on low-cost, commodity hardware.
- Provides high throughput data access to application data.
Cassandra
Cluster
- Cassandra DB is distrobuted over multiple machines that work together.
- Each node is a replica to handle failures
- nodes are in a cluster ring format
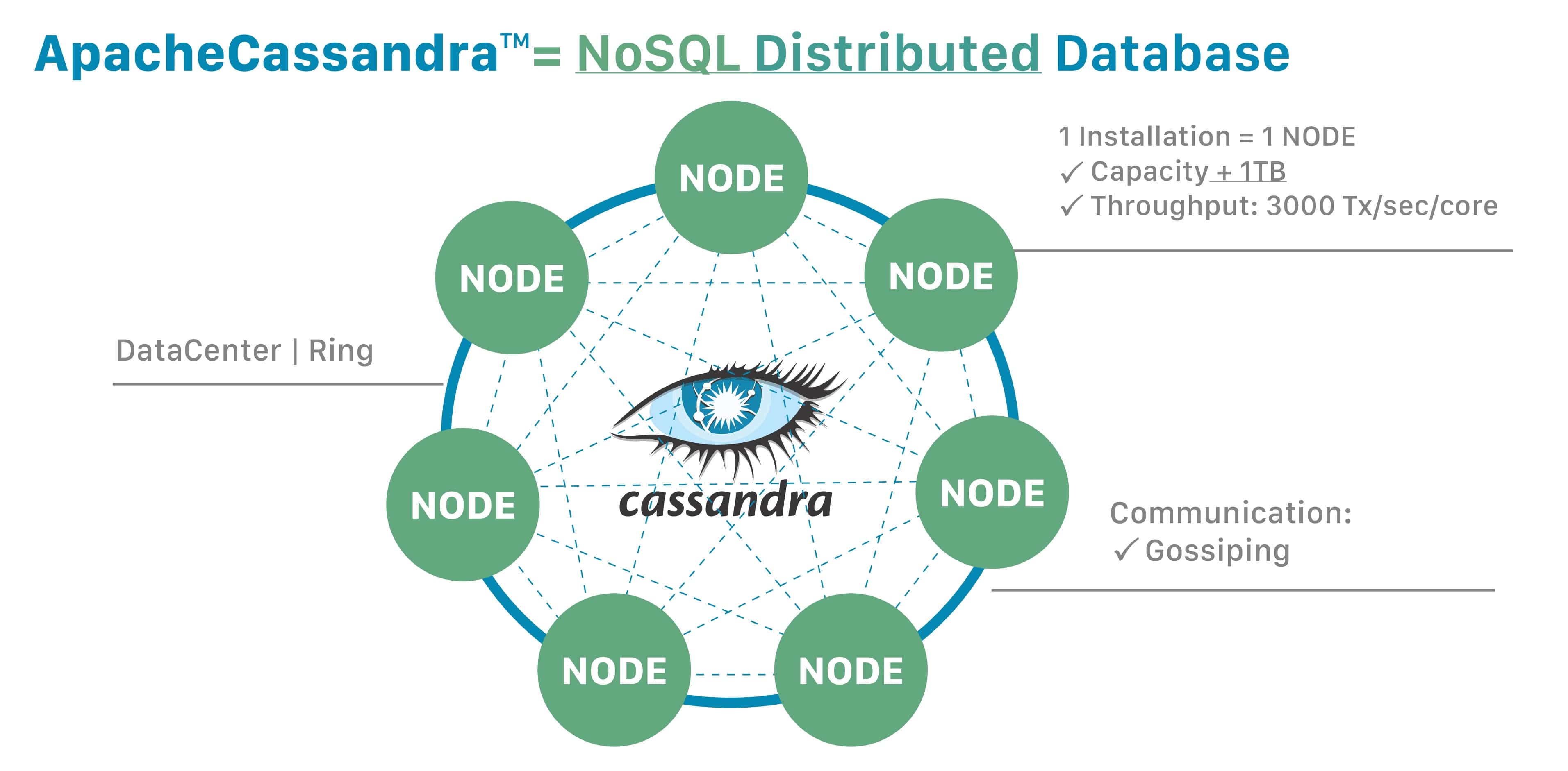
Keyspace
- Replication factor is the number of machines the information is stored on
- Replica placement strategy is simply the strategy to place replicas in the 'ring' shown above.
Strategies include
- Simple strategy (rack aware strategy)
- old network topology strategy (rack aware strategy)
- network topology strategy (datacenter-shared strategy)
- Column families, keyspace is a container for a list of one or more column families. A column family is a
collection of rows with ordered columns.
Apache Spark
- Spark was created to address the limitations present in MapReduce by doing processing in-memory avoiding steps
and reuing data across parallel operations.
- Only one step is needed with spark where the data is read into memory, operations are done, and the results are
written back making it much faster.
- Spark also reuses data by using in-memory cache to speed up machine learning algorithms that repeatedly call a
function on the same dataset.
- This all makes spark multiple times faster than MapReduce especially when doing machine learning and interactive
analytics.
Resilient Distributed Dataset (RDD)
- Every spark application has an abstraction of RDD, which is a collection of elements partitioned across nodes of
the cluster that can be opereated on in parallel.
- They are created by starting with a file in the Hadoop file system
- RDDs automatically recover from node failures.
Erlang
- Used for building concurrent software.
- Pros of use:
- It is a simple language to use
- It scales very well as once the deployment and integration is set up, scaling erlange nodes and spawning
new processess on different machines becomes easy.
- When a program fails it is able to re-span any failed process automatically making it a safe language to
use for concurrency.
- Cons:
- It has a convoluted setup process
- Is a dynamically typed language so it's possible for problems to not be found at compile time and
instead will be found during running of the code.
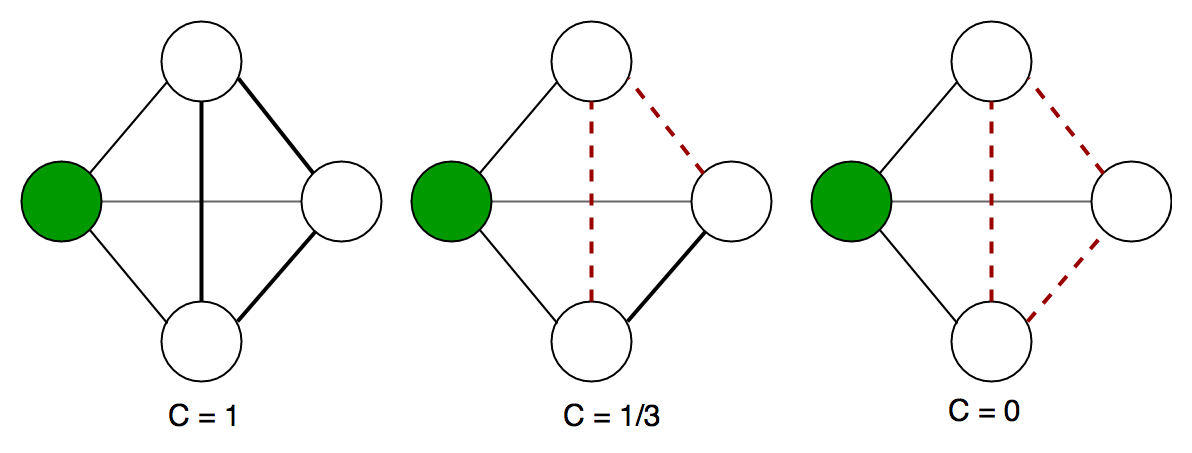
Local clustering coefficient
- The local clustering coefficient of a vertexx node is how close its neighbours are to being a complete graph
CAP Theorem
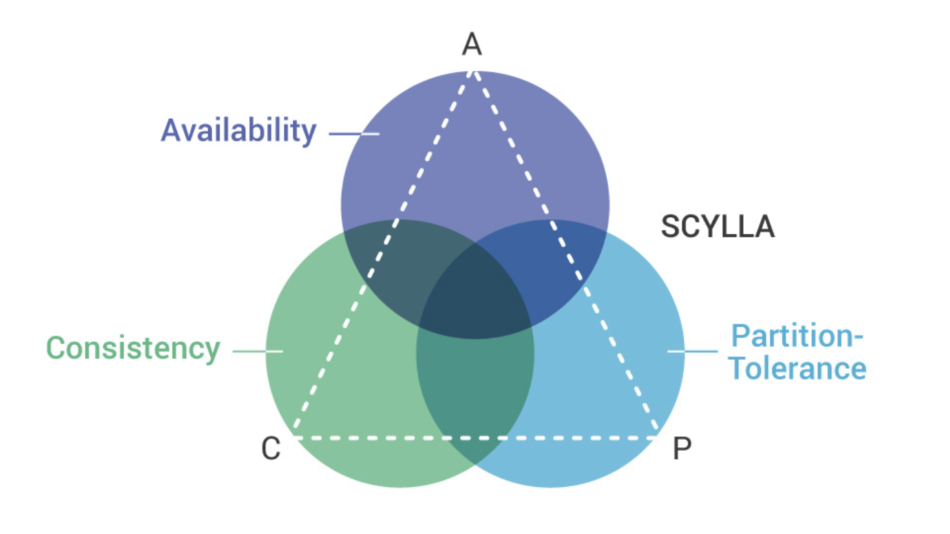
- Also named Brewer's theorem states that any distributed data store can provide only two of
the following three quarantees, but never all 3.
Three guarantees (only 2 at once):
- Consistency - Every read recieves the most recent write or an error
- Availability - Every request recieves a non error response, without the guarantee that it
contains the most recent write.
- Partition tolerance - The system continues to work despite messages being dropped or delayed by
network nodes.
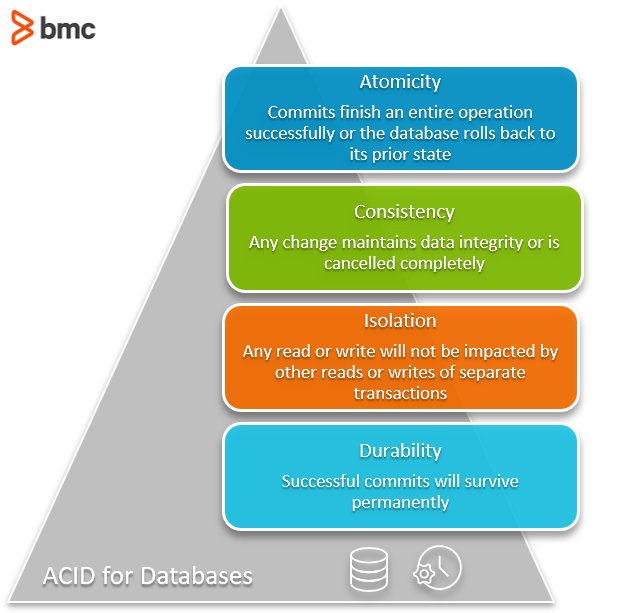
ACID vs BASE model of db functionality.
Acid details:
Base Stands for
- Basically Available - Rather than enforcing immediate consistency, BASE-modelled NoSQL
databases will ensure availability of data by spreading and replication it across the nodes of the database
cluster.
- Soft State - Due to the lack of immediate consistency data values may change over time, the
BASE model breaks off with the idea that a database must enforce its own consistency, leaving that to individual
developers.
- Eventually Consistent - the fact that BASE does not enforce immediate consistency does not mean
that it never achieves it. but until it does it's still possible to read data.
Base differences:
- ACID-compliant databases are better when consistency, predicatbility, and reliability are required.
- When growth is the highest priority, BASE is a good option as it's easier to scale it up and gives more
flexibility.
- BASE requires developers who are experienced and know how to deal with it's limitations of enforcing
consistency on their own.
Scala Basics
Means Scalable Language as it's entire purpose is to scale easily.
- it's a blend of oop and functional programming language with static typing.
- Brings in the best of both paradigms
- High level abstraction and conciseness of functional languages
- Flexibility, encapsulation and modularity from object oriented languages
- Compiles to JVM so can use java libraries and types
- order of magnitude less lines than java
- statically typed
Functional components:
- Operations map inputs to outputs instead of re-write so no side-effects
- no i=i+1 in functional language
- no global state, no loops, no destructive state
- Significantly easier concurrency
- The lack of side effects means no race conditions or deadlocks
- parallel programs are easier to write
- Very easily scaleable
- Share-nothing approch is ideal for distributed systems
- Many big data frameworks have binding for Scala so easier to write than in Java or Python
Basic Scala syntax
- val - immutable variable
- var - mutable variable
- val \:\ = \
- Data types Int, Byte, Short, Long, Char, Float, Double, Boolean, String
List info:
- Lists are immutable and have a recursive structure
- can 'add' to a list by doing x :: xs where x is the first element and xs is the current list.
- Functions for list
- head - first element
- tail - everython but the first element
- isEmpty
- ::: - list concatination
- length
- init, last
- reverse
- drop, take, splitAt
Array info:
- Similar to lists but they are mutable
- Not recursive.
- Defined similar to lists
- val = new Array[\][\]
- Can convert between the two with elements, toArray, toList
Input output in scala:
- println(\)
- Source.fromFile(\).getLines
Classes in Scala
class MyClass {}
val x = new MyClass